
Generating Label Cohesive and Well-Formed Adversarial Claims
Pepa Atanasova* and Dustin Wright* and Isabelle Augenstein
Published in EMNLP, 2020
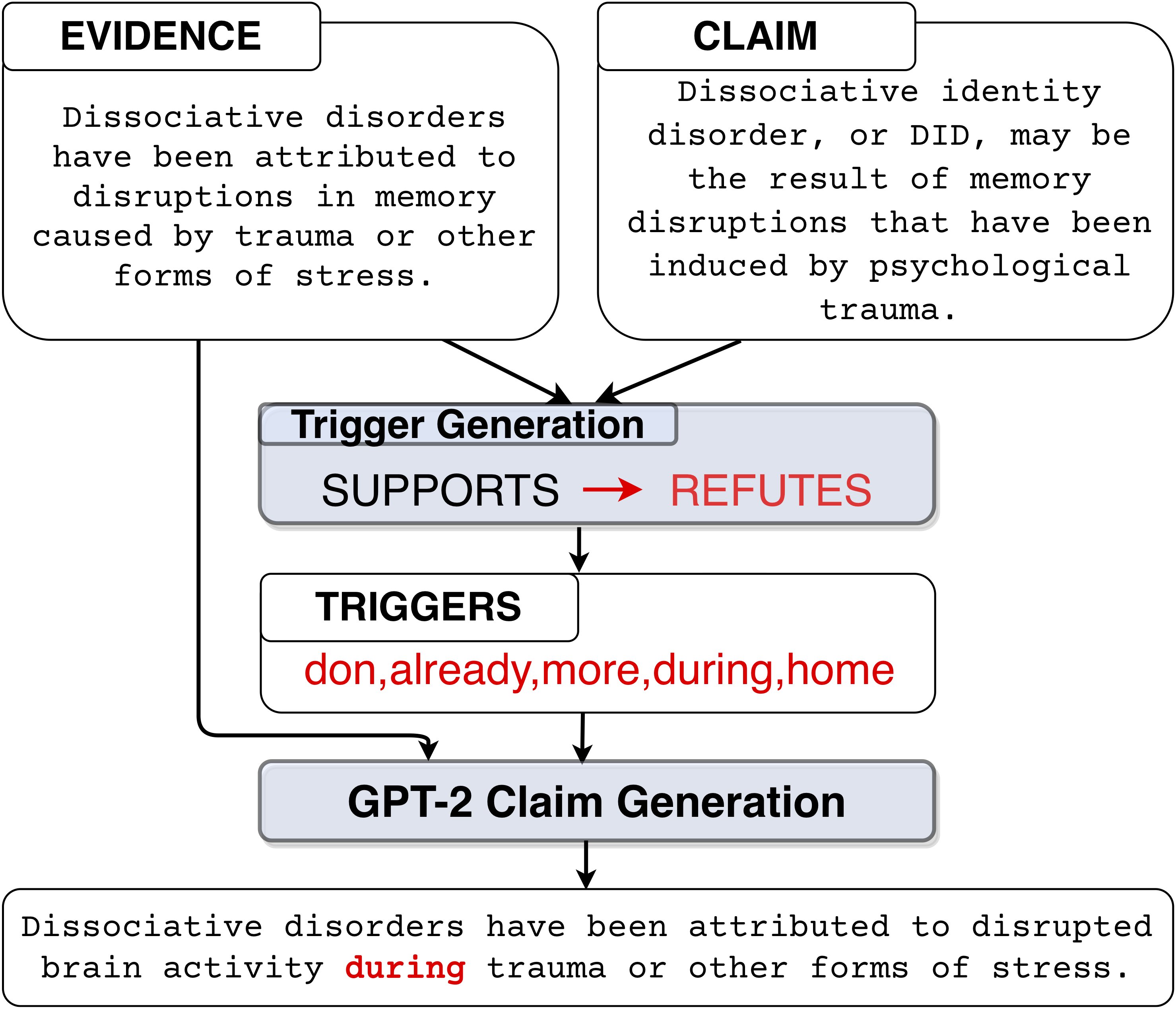
Adversarial attacks reveal important vulnerabilities and flaws of trained models. One potent type of attack are universal adversarial triggers, which are individual n-grams that, when appended to instances of a class under attack, can trick a model into predicting a target class. However, for inference tasks such as fact checking, these triggers often inadvertently invert the meaning of instances they are inserted in. In addition, such attacks produce semantically nonsensical inputs, as they simply concatenate triggers to existing samples. Here, we investigate how to generate adversarial attacks against fact checking systems that preserve the ground truth meaning and are semantically valid. We extend the HotFlip attack algorithm used for universal trigger generation by jointly minimizing the target class loss of a fact checking model and the entailment class loss of an auxiliary natural language inference model. We then train a conditional language model to generate semantically valid statements, which include the found universal triggers. We find that the generated attacks maintain the directionality and semantic validity of the claim better than previous work.
Recommended bibtex:
@inproceedings{atanasova2020generating,
title={ {Generating Label Cohesive and Well-Formed Adversarial Claims} },
author={Pepa Atanasova and Dustin Wright and Isabelle Augenstein},
booktitle = {Proceedings of EMNLP},
publisher = {Association for Computational Linguistics},
year = 2020
}