
Claim Check-Worthiness Detection as Positive Unlabelled Learning
Dustin Wright and Isabelle Augenstein
Published in Findings of EMNLP, 2020
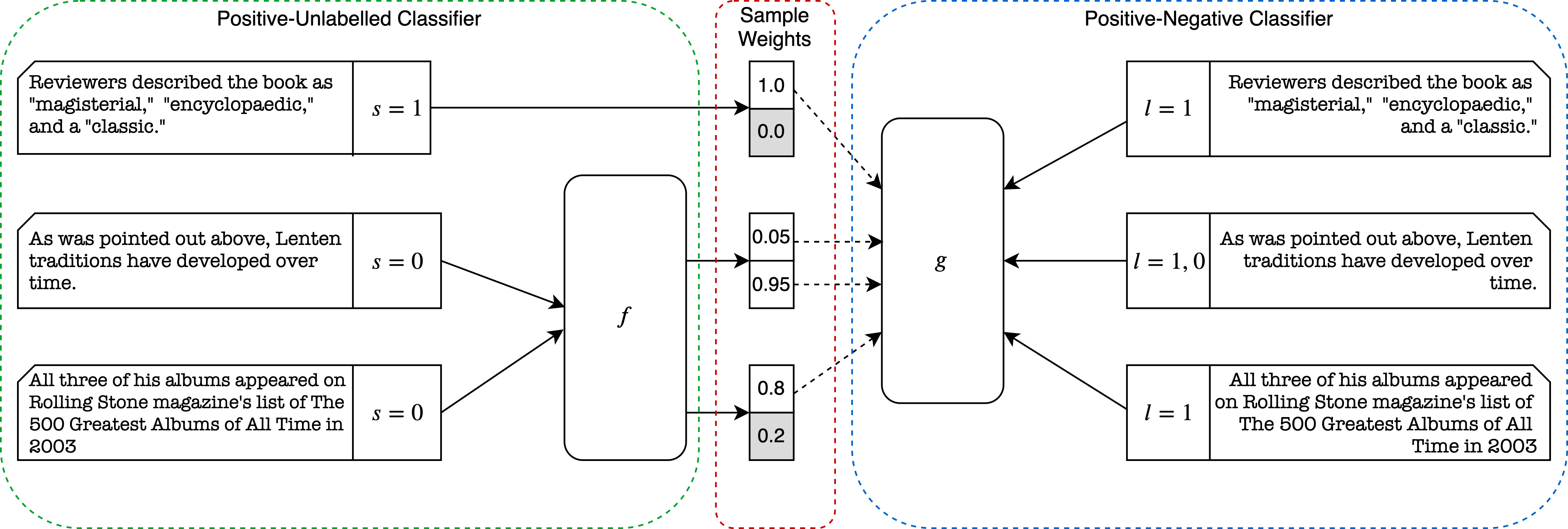
As the first step of automatic fact checking, claim check-worthiness detection is a critical component of fact checking systems. There are multiple lines of research which study this problem: check-worthiness ranking from political speeches and debates, rumour detection on Twitter, and citation needed detection from Wikipedia. To date, there has been no structured comparison of these various tasks to understand their relatedness, and no investigation into whether or not a unified approach to all of them is achievable. In this work, we illuminate a central challenge in claim check-worthiness detection underlying all of these tasks, being that they hinge upon detecting both how factual a sentence is, as well as how likely a sentence is to be believed without verification. As such, annotators only mark those instances they judge to be clear-cut check-worthy. Our best performing method is a unified approach which automatically corrects for this using a variant of positive unlabelled learning that finds instances which were incorrectly labelled as not check-worthy. In applying this, we out-perform the state of the art in two of the three tasks studied for claim check-worthiness detection in English.
Recommended bibtex:
@inproceedings{wright2020fact,
title={ {Claim Check-Worthiness Detection as Positive Unlabelled Learning} },
author={Dustin Wright and Isabelle Augenstein},
booktitle = {Findings of EMNLP},
publisher = {Association for Computational Linguistics},
year = 2020
}