
CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
Dustin Wright and Isabelle Augenstein
Published in Findings of ACL, 2021
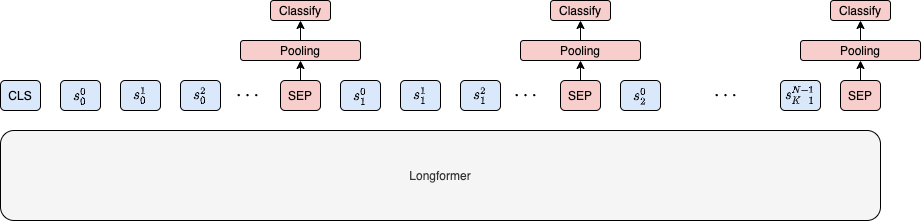
Scientific document understanding is challenging as the data is highly domain specific and diverse. However, datasets for tasks with scientific text require expensive manual annotation and tend to be small and limited to only one or a few fields. At the same time, scientific documents contain many potential training signals, such as citations, which can be used to build large labelled datasets. Given this, we present an in-depth study of cite-worthiness detection in English, where a sentence is labelled for whether or not it cites an external source. To accomplish this, we introduce CiteWorth, a large, contextualized, rigorously cleaned labelled dataset for cite-worthiness detection built from a massive corpus of extracted plain-text scientific documents. We show that CiteWorth is high-quality, challenging, and suitable for studying problems such as domain adaptation. Our best performing cite-worthiness detection model is a paragraph-level contextualized sentence labelling model based on Longformer, exhibiting a 5 F1 point improvement over SciBERT which considers only individual sentences. Finally, we demonstrate that language model fine-tuning with cite-worthiness as a secondary task leads to improved performance on downstream scientific document understanding tasks.
Recommended bibtex:
@inproceedings{wright2021citeworth,
title={ {CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding} },
author={Dustin Wright and Isabelle Augenstein},
booktitle = {Findings of ACL-IJCNLP},
publisher = {Association for Computational Linguistics},
year = 2021
}